基于深度强化学习的投资组合分配动态优化及优异成果展现
token钱包 2025年4月30日 15:14:05 token钱包安卓版下载 81

投资组合优化挑战
投资组合优化向来是金融领域的关键难题,资金需要在不同资产之间进行动态配置,这与投资者的收益和风险相关,传统方法存在诸多局限,其假设与实际情况相脱节,面对复杂的市场环境,适应性显著不足,在多变的市场里,传统方法很难灵活调整,无法满足投资者的需求。
经典的Markowitz框架计算投资组合收益时,是把资产权重和预期收益相乘,在实际动态交易里,市场情况复杂多变,预期收益和实际收益常常差距很大,仅靠预期收益做决策,会使投资者处于被动局面,比如股市出现突然波动时,基于预期的投资组合可能会遭受损失。
现有DRL模型问题
部分学者在使用DRL优化资产配置时失误明显,他们设计深度神经网络时考虑不周到,还忽略了资产权重约束,资产权重约束是指所有资产权重之和须为1,这一约束是保证投资组合合理的基础,一旦被忽略就可能导致投资组合失衡。


当前,DRL模型设计奖励函数主要依据投资组合回报,它在中国股市表现不好。一些研究者为让回测数据好看,采取固定投资权重的方式,这和DRL模型动态调整的初衷完全不一样。比如,有一个模型回测时采用固定权重,可是市场出现变化时,它没办法灵活应对。
新奖励函数探索
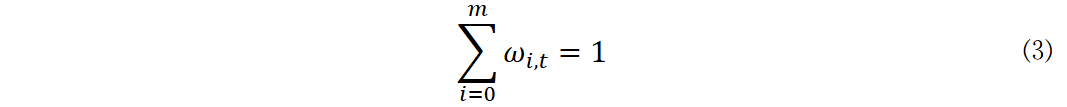
研究者们持续探索新的奖励函数,其目的在于提升DRL的资产优化性能,Wu等人定制了用于优化资产配置的夏普比率奖励函数,Almahdi等人把Calmar比率与递归强化学习相结合来优化美国和新兴市场的资产,这些新尝试给资产优化带来了新思路。
本研究提出了夏普比率奖励函数,该函数是专门为Actor - Critic算法设计的,它意义重大,能够增强模型稳定性,还可以优化动态投资组合过程,在市场波动时,稳定的模型能够更好地保护投资者资产,进而让投资组合更合理。
本研究具体应用
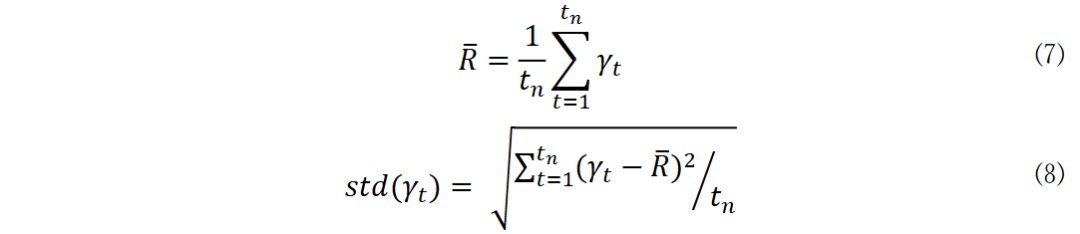
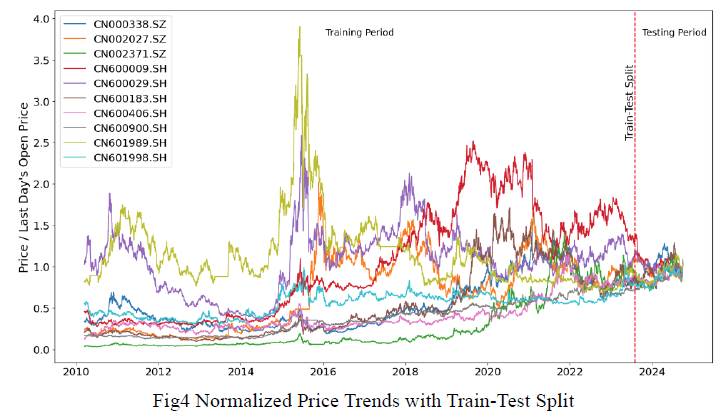
本研究是在长仓受限的情况下开展的,运用了DRL模型来优化CSI300成分股投资组合,还将该模型与多种计量经济学优化模型进行了系统对比,这种全方位的对比能够突显DRL模型的优势,经过实际数据验证,可以更清楚地看到不同模型的表现。
研究结果有力地证明了,DRL模型在资产配置优化方面是有成效的。在实际应用中,它可以帮助投资者更好地管理资产。这能够提高收益。例如在投资CSI300时,DRL模型能够根据市场变化动态调整资产权重。
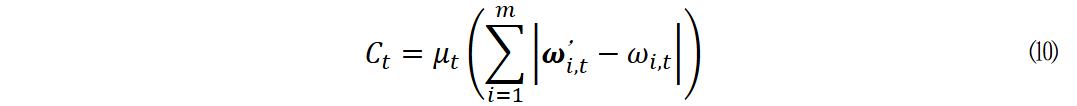
深度强化学习原理
在深度强化学习里,状态空间是代理与环境交互的根基,本研究依据有效市场假说,只用每日资产价格数据来构建状态空间,这种构建方式简便直接,能展现市场的实际状况。

深度强化学习将神经网络与强化学习框架相结合,借助在线统计推断来优化决策策略,其目的是使预期累积奖励最大化,在复杂市场中持续学习并调整策略,从而获取最佳投资回报,比如投资时依据市场实时数据动态调整投资决策。

DRL模型表现优势
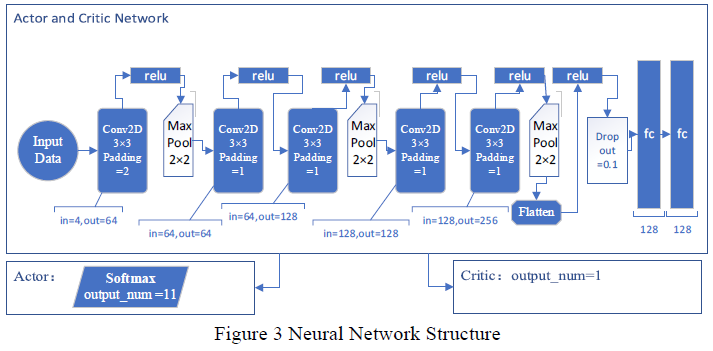
PPO算法构建的投资组合展现出良好的风险收益特性,这表明深度强化学习在投资组合管理领域具备巨大的应用潜力,它能够在控制风险的同时,获取较高收益,在市场出现波动时,PPO算法的投资组合能够更稳定地运行。
DRL模型在投资组合优化方面有出色表现,它的年化平均回报率是19.56%,夏普比率为1.5550,这表明它具备卓越的风险调整回报能力,在回测期间,DRL模型的各项指标比传统优化模型更具优势,你是否也想在投资中尝试运用这种深度强化学习模型?